Meta not too long ago launched its Llama 3 mannequin in two sizes with 8B and 70B parameters and open-sourced the fashions for the AI group. Whereas being a smaller 70B mannequin, Llama 3 has proven spectacular functionality, as evident from the LMSYS leaderboard. So now we have in contrast Llama 3 with the flagship GPT-4 mannequin to guage their efficiency in numerous exams. On that notice, let’s undergo our comparability between Llama 3 and GPT-4.
1. Magic Elevator Take a look at
Let’s first run the magic elevator test to guage the logical reasoning functionality of Llama 3 compared to GPT-4. And guess what? Llama 3 surprisingly passes the take a look at whereas the GPT-4 mannequin fails to offer the proper reply. That is fairly shocking since Llama 3 is simply skilled on 70 billion parameters whereas GPT-4 is skilled on an enormous 1.7 trillion parameters.
Bear in mind, we ran the take a look at on the GPT-4 mannequin hosted on ChatGPT (out there to paid ChatGPT Plus customers). It appears to be utilizing the older GPT-4 Turbo mannequin. We ran the identical take a look at on the recently-released GPT-4 mannequin (gpt-4-turbo-2024-04-09) by way of OpenAI Playground, and it handed the take a look at. OpenAI says that they’re rolling out the most recent mannequin to ChatGPT, however maybe it’s not out there on our account but.
There's a tall constructing with a magic elevator in it. When stopping on an excellent ground, this elevator connects to ground 1 as a substitute.
Beginning on ground 1, I take the magic elevator 3 flooring up. Exiting the elevator, I then use the steps to go 3 flooring up once more.
Which ground do I find yourself on?
Winner: Llama 3 70B, and gpt-4-turbo-2024-04-09
Observe: GPT-4 loses on ChatGPT Plus

2. Calculate Drying Time
Subsequent, we ran the basic reasoning query to check the intelligence of each fashions. On this take a look at, each Llama 3 70B and GPT-4 gave the proper reply with out delving into arithmetic. Good job Meta!
If it takes 1 hour to dry 15 towels underneath the Solar, how lengthy will it take to dry 20 towels?
Winner: Llama 3 70B, and GPT-4 by way of ChatGPT Plus

Really helpful Articles
I Obtained Entry to Gemini 1.5 Professional, and It’s Higher Than GPT-4 and Gemini 1.0 Extremely
Feb 28, 2024
3. Discover the Apple
After that, I requested one other query to match the reasoning functionality of Llama 3 and GPT-4. On this take a look at, the Llama 3 70B mannequin comes near giving the suitable reply however misses out on mentioning the field. Whereas, the GPT-4 mannequin rightly solutions that “the apples are nonetheless on the bottom contained in the field”. I’m going to present it to GPT-4 on this spherical.
There's a basket and not using a backside in a field, which is on the bottom. I put three apples into the basket and transfer the basket onto a desk. The place are the apples?
Winner: GPT-4 by way of ChatGPT Plus

4. Which is Heavier?
Whereas the query appears fairly easy, many AI fashions fail to get the suitable reply. Nevertheless, on this take a look at, each Llama 3 70B and GPT-4 gave the right reply. That stated, Llama 3 generally generates flawed output so preserve that in thoughts.
What's heavier, a kilo of feathers or a pound of metal?
Winner: Llama 3 70B, and GPT-4 by way of ChatGPT Plus

5. Discover the Place
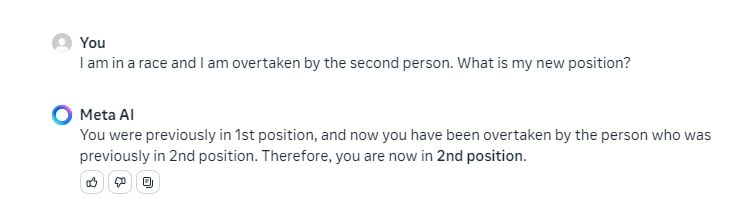
Subsequent, I requested a easy logical query and each fashions gave an accurate response. It’s fascinating to see a a lot smaller Llama 3 70B mannequin rivaling the top-tier GPT-4 mannequin.
I'm in a race and I'm overtaken by the second particular person. What's my new place?
Winner: Llama 3 70B, and GPT-4 by way of ChatGPT Plus
Really helpful Articles
Claude 3 Opus vs GPT-4 vs Gemini 1.5 Professional AI Fashions Examined
Mar 6, 2024
6. Remedy a Math Drawback
Subsequent, we ran a posh math problem on each Llama 3 and GPT-4 to seek out which mannequin wins this take a look at. Right here, GPT-4 passes the take a look at with flying colours, however Llama 3 fails to give you the suitable reply. It’s not shocking although. The GPT-4 mannequin has scored nice on the MATH benchmark. Understand that I explicitly requested ChatGPT to not use Code Interpreter for mathematical calculations.
Decide the sum of the y-coordinates of the 4 factors of intersection of y = x^4 - 5x^2 - x + 4 and y = x^2 - 3x.
Winner: GPT-4 by way of ChatGPT Plus

7. Comply with Consumer Directions
Following person directions is essential for an AI mannequin and Meta’s Llama 3 70B mannequin excels at it. It generated all 10 sentences ending with the phrase “mango”. GPT-4 may solely generate eight such sentences.
Generate 10 sentences that finish with the phrase "mango"
Winner: Llama 3 70B

Really helpful Articles
Gemini Extremely vs GPT-4: Google Nonetheless Lacks the Secret Sauce
Feb 12, 2024
8. NIAH Take a look at
Though Llama 3 at present doesn’t have a protracted context window, we nonetheless did the NIAH take a look at to verify its retrieval functionality. The Llama 3 70B mannequin helps a context size of as much as 8K tokens. So I positioned a needle (a random assertion) inside a 35K-character lengthy textual content (8K tokens) and requested the mannequin to seek out the data. Surprisingly, the Llama 3 70B discovered the textual content very quickly. GPT-4 additionally had no downside discovering the needle.
After all, it is a small context, however when Meta releases a Llama 3 mannequin with a a lot bigger context window, I’ll take a look at it once more. However for now, Llama 3 exhibits nice retrieval functionality.
Winner: Llama 3 70B, and GPT-4 by way of ChatGPT Plus
Really helpful Articles
Gemini 1.5 Professional Now Listens to Audio and Is Obtainable to All
Apr 10, 2024
I Examined Meta AI on WhatsApp And Right here’s Every little thing It’s Succesful Of
Apr 14, 2024
Llama 3 vs GPT-4: The Verdict
In nearly the entire exams, the Llama 3 70B mannequin has proven spectacular capabilities, be it superior reasoning, following person directions, or retrieval functionality. Solely in mathematical calculations, it lags behind the GPT-4 mannequin. Meta says that Llama 3 has been skilled on a bigger coding dataset so its coding efficiency must also be nice.
Keep in mind that we’re evaluating a a lot smaller mannequin with the GPT-4 mannequin. Additionally, Llama 3 is a dense mannequin whereas GPT-4 is constructed on the MoE structure consisting of 8x 222B fashions. It goes on to point out that Meta has carried out a exceptional job with the Llama 3 household of fashions. When the 500B+ Llama 3 mannequin drops sooner or later, it would carry out even higher and will beat the perfect AI fashions on the market.
It’s secure to say that Llama 3 has upped the sport, and by open-sourcing the mannequin, Meta has closed the hole considerably between proprietary and open-source fashions. We did all these exams on an Instruct mannequin. Wonderful-tuned fashions on Llama 3 70B would ship distinctive efficiency. Other than OpenAI, Anthropic, and Google, Meta has now formally joined the AI race.