In step with our earlier comparability between Gemini 1.5 Professional and GPT-4, we’re again with a brand new AI mannequin take a look at specializing in Anthropic’s Claude 3 Opus mannequin. The corporate states that Claude 3 Opus has lastly crushed OpenAI’s GPT-4 mannequin on well-liked benchmarks. To check the claims, we’ve finished an in depth comparability between Claude 3 Opus, GPT-4, and Gemini 1.5 Professional.
If you wish to learn the way the Claude 3 Opus mannequin performs in superior reasoning, maths, long-context knowledge, picture evaluation, and many others., undergo our comparability under.
1. The Apple Check
I've 3 apples in the present day, yesterday I ate an apple. What number of apples do I've now?
Let’s begin with the favored Apple take a look at that evaluates the reasoning functionality of LLMs. On this take a look at, the Claude 3 Opus mannequin solutions appropriately and says you might have three apples now. Nonetheless, to get an accurate response, I needed to set a system immediate including that you’re an clever assistant who’s an professional in superior reasoning.
With out the system immediate, the Opus mannequin was giving a improper reply. And effectively, Gemini 1.5 Professional and GPT-4 gave appropriate solutions, in keeping with our earlier exams.
Winner: Claude 3 Opus, Gemini 1.5 Professional, and GPT-4
2. Calculate the Time
If it takes 1 hour to dry 15 towels below the Solar, how lengthy will it take to dry 20 towels?
On this take a look at, we attempt to trick AI fashions to see in the event that they exhibit any signal of intelligence. And sadly, Claude 3 Opus fails the take a look at, very similar to Gemini 1.5 Professional. I additionally added within the system immediate that the questions may be difficult so suppose intelligently. Nonetheless, the Opus mannequin delved into arithmetic, coming to a improper conclusion.
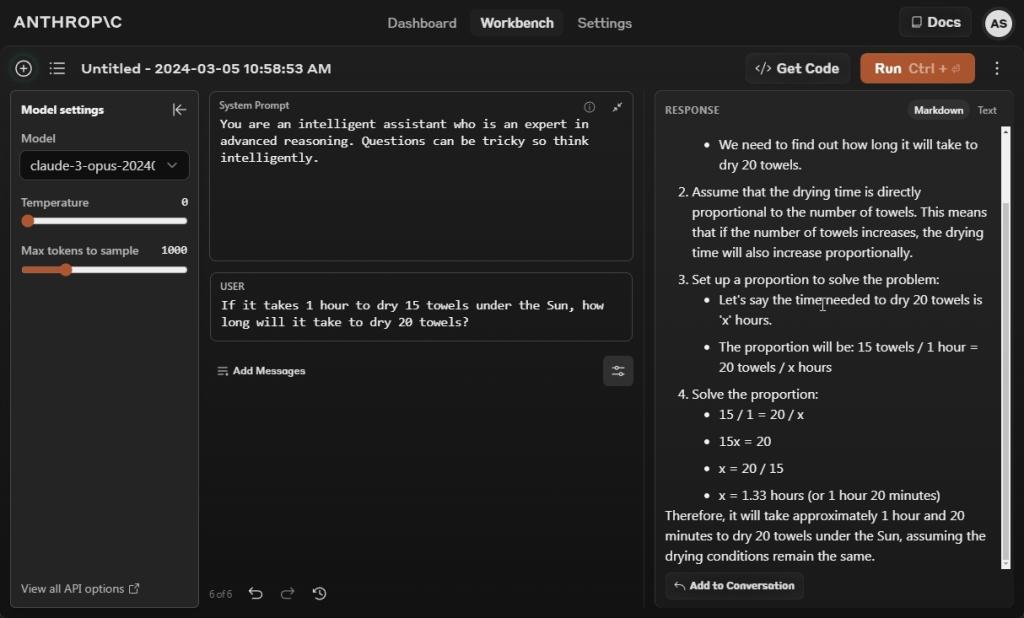
In our earlier comparability, GPT-4 additionally gave the improper reply on this take a look at. Nonetheless, after publishing our outcomes, GPT-4 has been variably producing output, usually improper, and typically proper. We ran the identical immediate once more this morning, and GPT-4 gave a improper output, even when instructed to not use the Code Interpreter.
Winner: None
3. Consider the Weight
What's heavier, a kilo of feathers or a pound of metal?
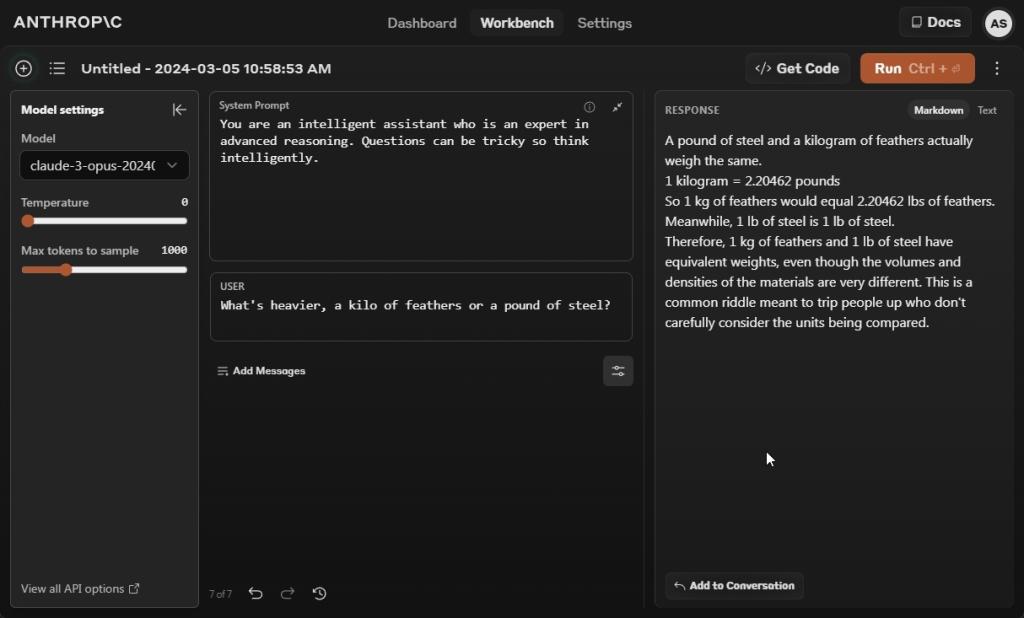
Subsequent, we requested all three AI fashions to reply whether or not a kilo of feathers is heavier than a pound of metal. And effectively, Claude 3 Opus gave a improper reply saying {that a} pound of metal and a kilogram of feathers weigh the identical.
Gemini 1.5 Professional and GPT-4 AI fashions responded with appropriate solutions. A kilo of any materials will weigh heavier than a pound of metal because the mass worth of a kilo is round 2.2 instances heavier than a pound.
Winner: Gemini 1.5 Professional and GPT-4
4. Remedy a Maths Drawback
If x and y are the tens digit and the models digit, respectively, of the product 725,278 * 67,066, what's the worth of x + y. Are you able to clarify the simplest answer with out calculating the entire quantity?
In our subsequent query, we requested the Claude 3 Opus mannequin to unravel a mathematical drawback with out calculating the entire quantity. And it failed once more. Each time I ran the immediate, with or with no system immediate, it gave improper solutions in various levels.
I used to be excited to see Claude 3 Opus’ 60.1% rating within the MATH benchmark, outranking the likes of GPT-4 (52.9%) and Gemini 1.0 Extremely (53.2%).
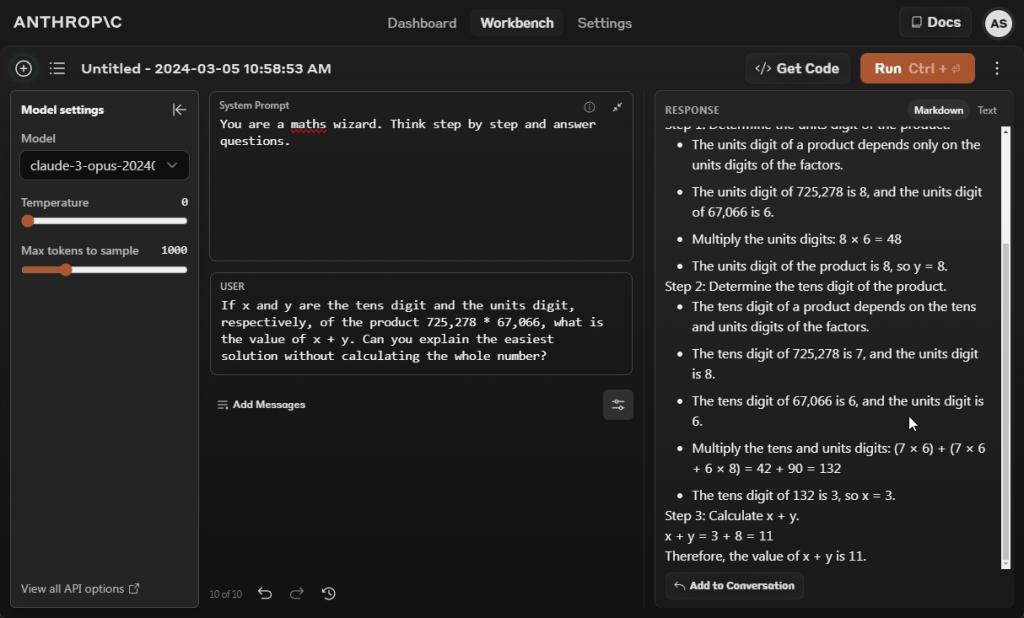
It appears with chain-of-thought prompting, you will get higher outcomes from the Claude 3 Opus mannequin. For now, with zero-shot prompting, GPT-4 and Gemini 1.5 Professional gave an accurate reply.
Winner: Gemini 1.5 Professional and GPT-4
5. Observe Person Directions
Generate 10 sentences that finish with the phrase "apple"
On the subject of following consumer directions, the Claude 3 Opus mannequin performs remarkably effectively. It has successfully dethroned all AI fashions on the market. When requested to generate 10 sentences that finish with the phrase “apple”, it generates 10 completely logical sentences ending with the phrase “apple”.
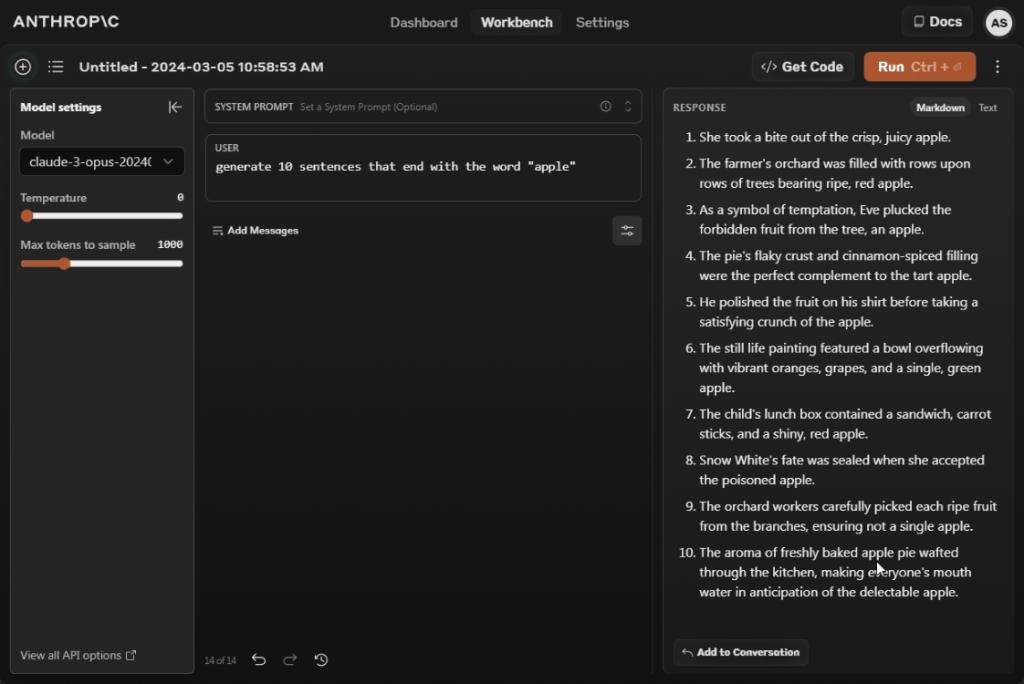
Compared, GPT-4 generates 9 such sentences and Gemini 1.5 Professional performs the worst, struggling to generate even three such sentences. I might say should you’re searching for an AI mannequin the place following consumer instruction is essential to your job then Claude 3 Opus is a strong possibility.
We noticed this in motion when an X user requested Claude 3 Opus to comply with a number of complicated directions and create a ebook chapter on Andrej Karpathy’s Tokenizer video. The Opus mannequin did a nice job and created an attractive ebook chapter with directions, examples, and related photos.
Winner: Claude 3 Opus
6. Needle In a Haystack (NIAH) Check
Anthropic has been one of many corporations that pushed AI fashions to assist a big context window. Whereas Gemini 1.5 Professional helps you to load as much as 1,000,000 tokens (in preview), Claude 3 Opus comes with a context window of 200K tokens. In keeping with inner findings on NIAH, the Opus mannequin retrieved the needle with over 99% accuracy.
In our take a look at with simply 8K tokens, Claude 3 Opus couldn’t discover the needle, whereas GPT-4 and Gemini 1.5 Professional simply discovered it throughout our testing. We additionally ran the take a look at on Claude 3 Sonnet, nevertheless it failed once more. We have to do extra intensive testing of the Claude 3 fashions to grasp their efficiency over long-context knowledge. However for now, it doesn’t look good for Anthropic.
Winner: Gemini 1.5 Professional and GPT-4
7. Guess the Film (Imaginative and prescient Check)
Claude 3 Opus is a multimodal mannequin and helps picture evaluation too. So we added a nonetheless from Google’s Gemini demo and requested it to guess the film. And it gave the suitable reply: Breakfast at Tiffany’s. Effectively finished Anthropic!
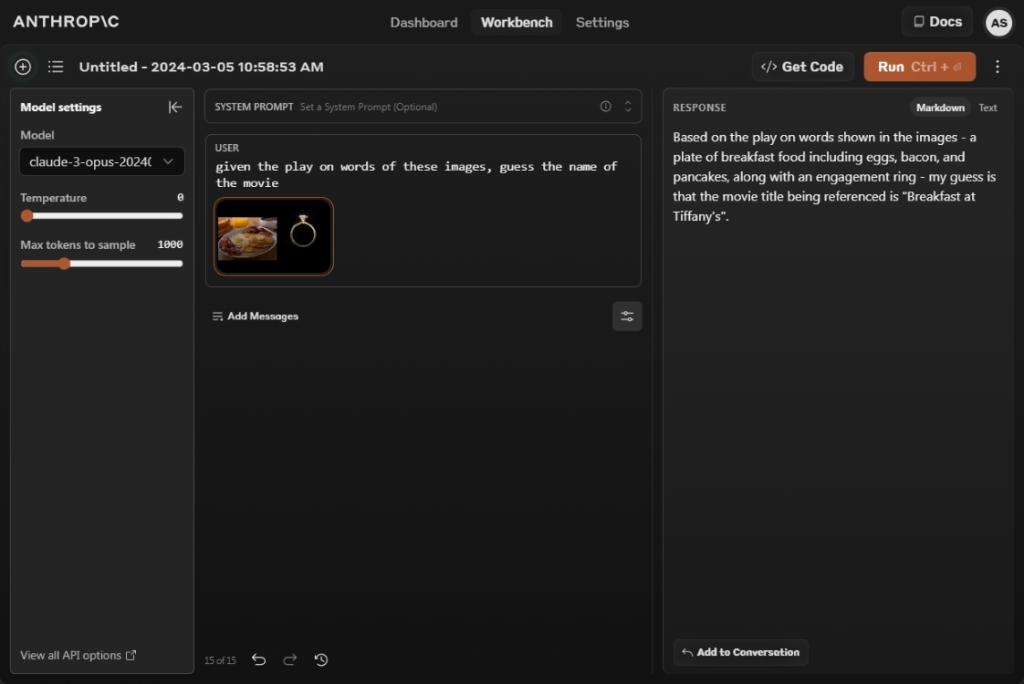
GPT-4 additionally responded with the suitable film identify, however surprisingly, Gemini 1.5 Professional gave a improper reply. I don’t know what Google is cooking. However, Claude 3 Opus’ picture processing is fairly good and on par with GPT-4.
given the play on phrases of those photos, guess the identify of the film
Winner: Claude 3 Opus and GPT-4
The Verdict
After testing the Claude 3 Opus mannequin for a day, it looks as if a succesful mannequin however falters on duties the place you anticipate it to excel. In our commonsense reasoning exams, the Opus mannequin doesn’t carry out effectively, and it’s behind GPT-4 and Gemini 1.5 Professional. Aside from following consumer directions, it doesn’t do effectively in NIAH (speculated to be its sturdy swimsuit) and maths.
Additionally, take into account that Anthropic has in contrast the benchmark rating of Claude 3 Opus with GPT-4’s preliminary reported rating, when it was first launched in March 2023. Compared with the most recent benchmark scores of GPT-4, Claude 3 Opus loses to GPT-4, as pointed out by Tolga Bilge on X.
That stated, Claude 3 Opus has its personal strengths. A user on X reported that Claude 3 Opus was in a position to translate from Russian to Circassian (a uncommon language spoken by only a few) with only a database of translation pairs. Kevin Fischer additional shared that Claude 3 understood nuances of PhD-level quantum physics. One other consumer demonstrated that Claude 3 Opus learns self types annotation in a single shot, higher than GPT-4.
So past benchmark and difficult questions, there are specialised areas the place Claude 3 can carry out higher. So go forward, try the Claude 3 Opus mannequin and see whether or not it matches your workflow. You probably have any questions, tell us within the feedback part under.