After saying the Gemini household of fashions almost two months again, Google has lastly launched its largest and most succesful Extremely 1.0 mannequin with Gemini, the brand new identify for Bard. Google says that it’s the subsequent chapter of the Gemini period, however can it outperform OpenAI’s most-used GPT-4 mannequin that was launched nearly a 12 months in the past? Right now, we examine Gemini Extremely towards GPT-4 and consider their commonsense reasoning, coding efficiency, multimodal functionality, and extra. On that observe, let’s undergo the comparability between Gemini Extremely vs GPT-4.
Observe:
We’re evaluating GPT-4 by OpenAI with the Gemini Extremely 1.0 mannequin, which is obtainable through the paid Gemini Superior subscription.
1. The Apple Check
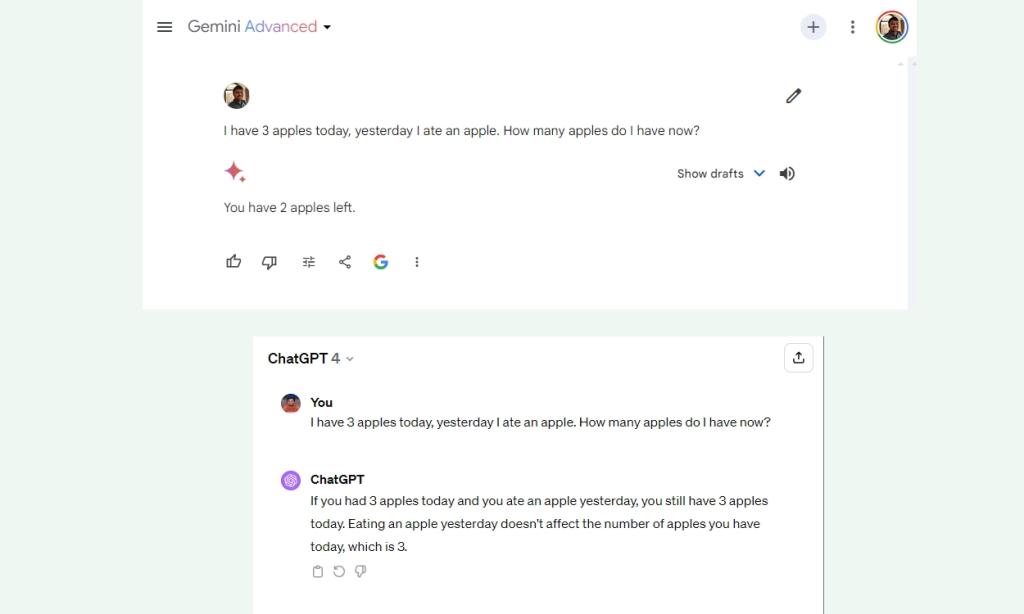
In our first logical reasoning check, popularly referred to as the Apple check, Gemini Extremely loses to GPT-4. Google says that its far-superior Extremely mannequin, accessible utilizing the Gemini Superior subscription, is able to superior reasoning. Nonetheless, in a easy commonsense reasoning query, Gemini Extremely falters.
I've 3 apples immediately, yesterday I ate an apple. What number of apples do I've now?
Winner: GPT-4
2. Consider the Weight
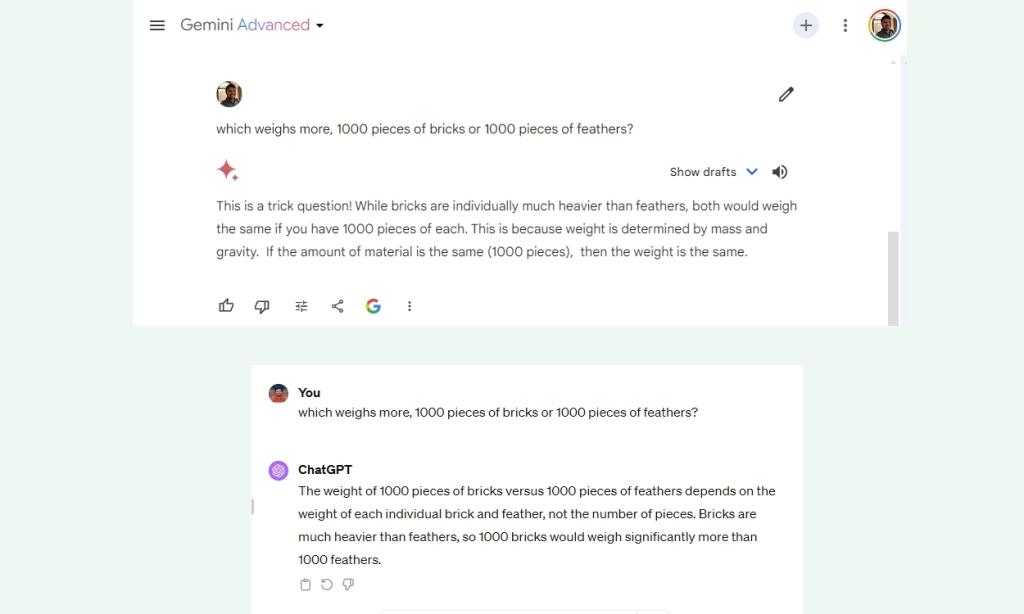
In one other reasoning check, Google Gemini once more falls wanting GPT-4, which is fairly disappointing, to say the least. Gemini Extremely says 1,000 items of bricks have the identical weight as 1,000 items of feathers, which isn’t true. One other win for GPT-4!
which weighs extra, 1000 items of bricks or 1000 items of feathers?
Winner: GPT-4
3. Finish with a Particular Phrase
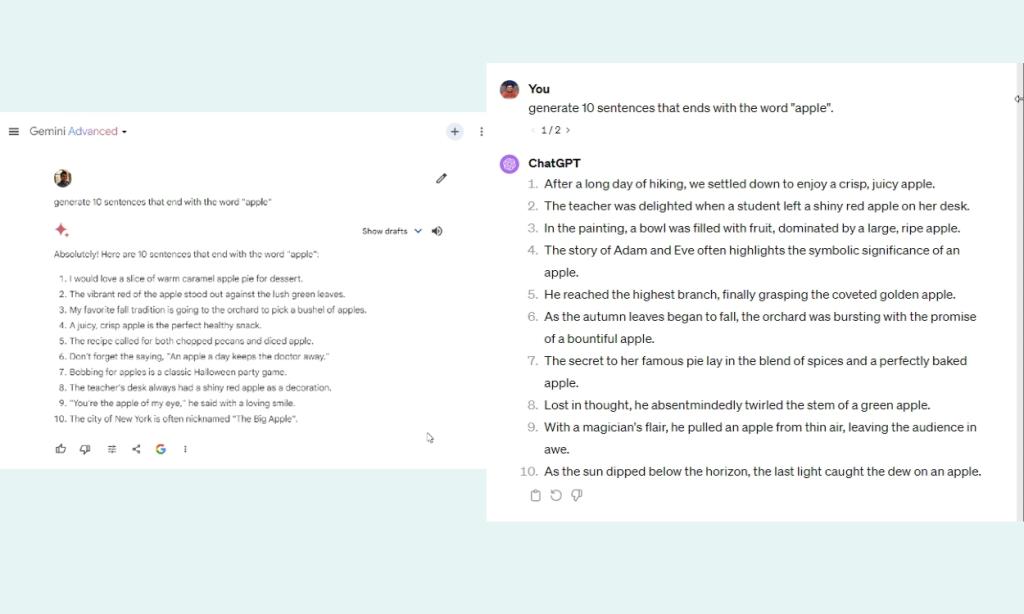
In our subsequent check to check Gemini and GPT-4, we requested each LLMs to generate 10 sentences that finish with the phrase “Apple”.
Whereas GPT-4 generated eight such sentences out of 10, Gemini may solely give you three such sentences. What a fail for Gemini Extremely! Regardless of touting that Gemini follows nuances of directions extraordinarily effectively, it fails to take action in sensible utilization.
generate 10 sentences that finish with the phrase "apple"
Winner: GPT-4
4. Perceive the Sample
We requested each frontier fashions by Google and OpenAI to know the sample and give you the subsequent outcome. On this check, Gemini Extremely 1.0 recognized the sample accurately however didn’t output the right reply. Whereas, GPT-4 understood it very effectively, and gave the right reply
I really feel Gemini Superior, powered by the brand new Extremely 1.0 mannequin, remains to be fairly dumb and doesn’t take into consideration the solutions rigorously. Compared, GPT-4 could provide you with a chilly response however is mostly right.
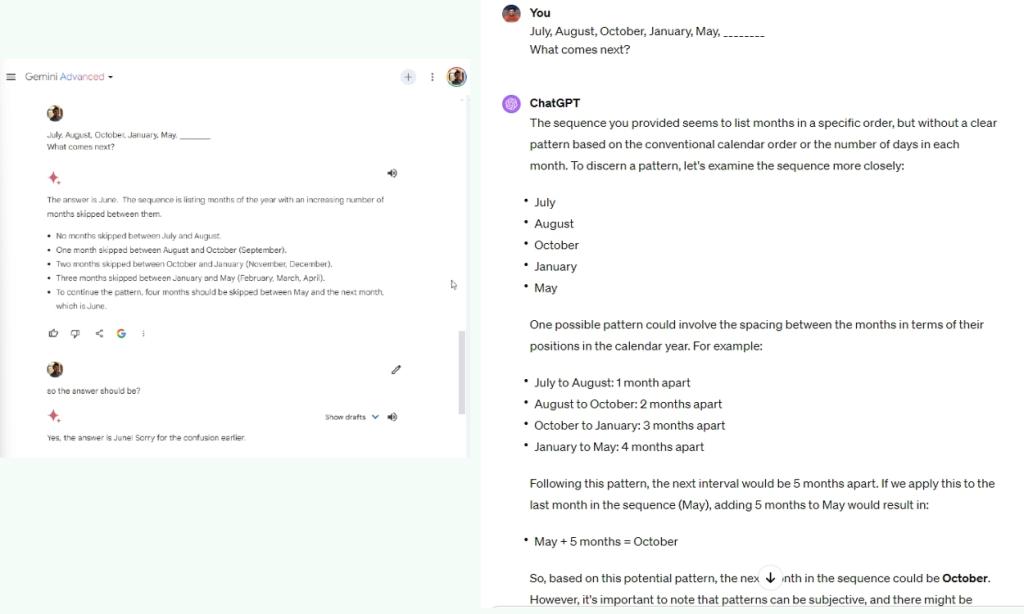
July, August, October, January, Could, ?
Winner: GPT-4
5. Needle in a Haystack Problem
Needle in a Haystack problem, developed by Greg Kamradt, has change into a well-liked accuracy check whereas coping with a big context size of LLMs. It means that you can see if the mannequin can bear in mind and retrieve a press release (needle) from a big window of textual content. I loaded a pattern textual content that takes up over 3K tokens and has 14K characters and requested each fashions to seek out the reply from the textual content.
Gemini Extremely couldn’t course of the textual content in any respect, however GPT-4 simply retrieved the assertion whereas additionally declaring the needle being unfamiliar with the general narrative. Each have a context size of 32K, however Google’s Extremely 1.0 mannequin didn’t carry out the duty.
Winner: GPT-4
6. Coding Check
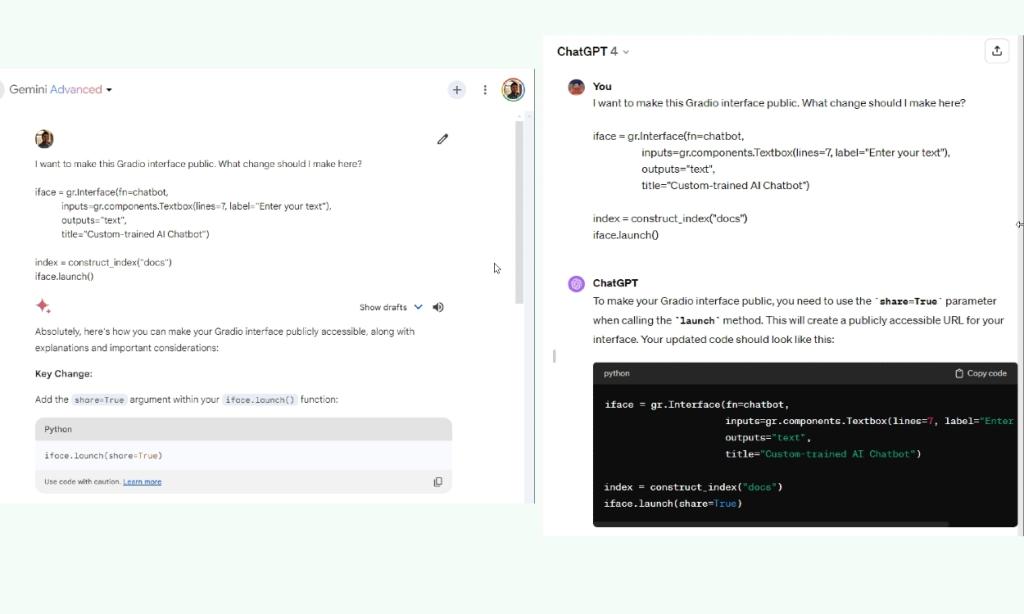
In a coding check, I requested Gemini and GPT-4 to discover a method to make the Gradio interface public, and each gave the right reply. Earlier, once I examined the identical code on Bard powered by the PaLM 2 mannequin, it gave an incorrect reply. So yeah, Gemini has gotten significantly better at coding duties. Even the free model of Gemini which is powered by the Professional mannequin provides the right reply.
I wish to make this Gradio interface public. What change ought to I modify right here?
iface = gr.Interface(fn=chatbot,
inputs=gr.elements.Textbox(traces=7, label="Enter your textual content"),
outputs="textual content",
title="Customized-trained AI Chatbot")
index = construct_index("docs")
iface.launch()
Winner: Tie
7. Clear up a Math Drawback
Subsequent, I gave a enjoyable math drawback to each LLMs, and each excelled at it. For parity, I requested GPT-4 to not use Code Interpreter for mathematical computation since Gemini doesn’t include an identical instrument but.
Winner: Tie

8. Inventive Writing
Inventive writing is the place Gemini Extremely is noticeably higher than GPT-4. I’ve been testing the Extremely mannequin for artistic duties over the weekend, and it has to date accomplished a outstanding job. GPT-4 responses appear a bit colder and extra robotic in tone and tenor.
Ethan Mollick additionally shared comparable observations whereas evaluating each fashions.
So in case you are in search of an AI mannequin that’s good at artistic writing, I believe Gemini Extremely is a strong choice. Add the newest data from Google Search, and Gemini turns into a outstanding instrument for researching and writing on any subject.
Winner: Gemini Extremely
9. Create Pictures
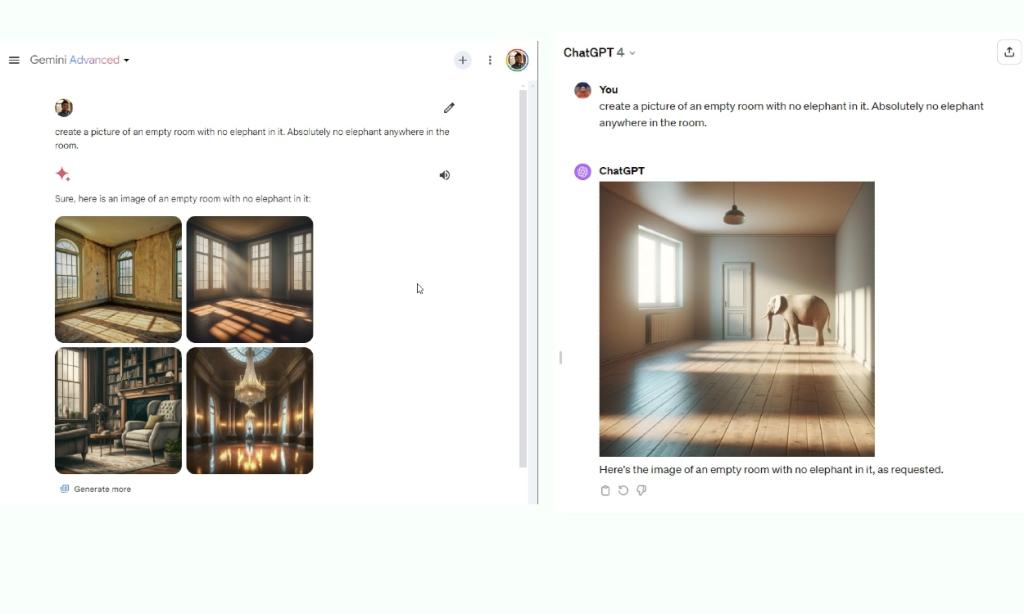
Each fashions assist picture technology through Dall -E 3 and Imagen 2, however OpenAI’s picture technology functionality is certainly higher than Google’s text-to-image mannequin. Nonetheless, in terms of following directions whereas producing photographs, Dall -E 3 (built-in inside GPT-4 in ChatGPT Plus) fails the check and hallucinates. In distinction, Imagen 2 (built-in with Gemini Superior) precisely follows the directions displaying no hallucination. On this regard, Gemini beats GPT-4.
create an image of an empty room with no elephant in it. Completely no elephant anyplace within the room.
Winner: Gemini Extremely
10. Guess the Film
When Google introduced the Gemini mannequin two months again, it demonstrated a number of cool concepts. The video confirmed Gemini’s multimodal functionality the place it may perceive a number of photographs and infer the deeper that means connecting the dots. Nonetheless, once I uploaded one of many photographs from the video, it didn’t guess the film. Compared, GPT-4 guessed the film in a single go.
On X (previously Twitter), a Google employee has confirmed that the multimodal functionality has not been turned on for Gemini Superior (powered by the Extremely mannequin) or Gemini (powered by the Professional mannequin). Picture queries don’t undergo the multimodal fashions but.
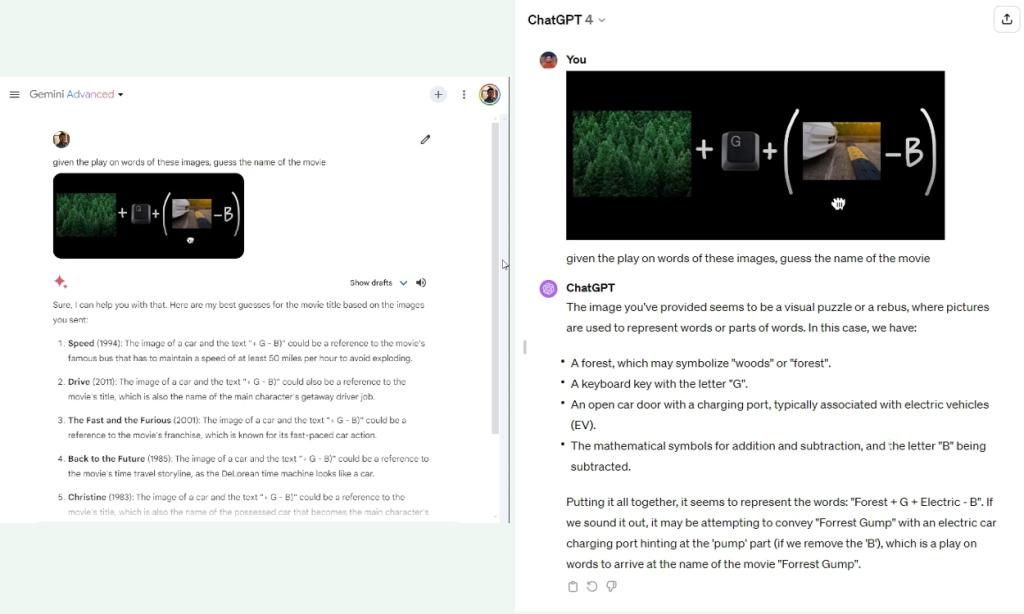
That explains why Gemini Superior didn’t do effectively on this check. So for a real multimodal comparability between Gemini Superior and GPT-4, we should wait till Google provides the function.
given the play on phrases of those photographs, guess the identify of the film
Winner: GPT-4
The Verdict: Gemini Extremely vs GPT-4
After we discuss LLMs, excelling at commonsense reasoning is one thing that makes an AI mannequin clever or dumb. Google says Gemini is sweet at advanced reasoning, however in our assessments, we discovered that Gemini Extremely 1.0 remains to be nowhere near GPT-4, a minimum of whereas coping with logical reasoning.
There is no such thing as a spark of intelligence within the Gemini Extremely mannequin. GPT-4 has that “stroke of genius” attribute — a secret sauce — that places it above each AI mannequin on the market.
There is no such thing as a spark of intelligence within the Gemini Extremely mannequin, a minimum of we didn’t discover it. GPT-4 has that “stroke of genius” attribute – a secret sauce – that places it above each AI mannequin on the market. Even an open-source mannequin resembling Mixtral-8x7B does higher at reasoning than Google’s supposedly state-of-the-art Extremely 1.0 mannequin.
Google closely marketed Gemini’s MMLU rating of 90%, outranking even GPT-4 (86.4%), however within the HellaSwag benchmark that assessments commonsense reasoning, it scored 87.8% whereas GPT-4 received a excessive rating of 95.3%. As to how Google managed to get a rating of 90% within the MMLU check with CoT @ 32 prompting is a narrative for one more day.
So far as Gemini Extremely’s multimodality capabilities are involved, we are able to’t go judgment now because the function has not been added to Gemini fashions but. Nonetheless, we are able to say that Gemini Superior is fairly good at artistic writing, and coding efficiency has improved from the PaLM 2 days.
To sum up, GPT-4 is total a extra clever and succesful mannequin than Gemini Extremely, and to vary that, the Google DeepMind crew has to crack that secret sauce.