Whereas utilizing ChatGPT, particularly with the GPT-4 mannequin, you need to have observed how gradual the mannequin responds to queries. To not point out, voice assistants based mostly on giant language fashions like ChatGPT’s Voice Chat characteristic or the not too long ago launched Gemini AI, which changed Google Assistant on Android telephones are even slower because of the excessive latency of LLMs. However all of that’s more likely to change quickly, because of Groq’s highly effective new LPU (Language Processing Unit) inference engine.
Groq has taken the world unexpectedly. Thoughts you, this isn’t Elon Musk’s Grok, which is an AI mannequin accessible on X (previously Twitter). Groq’s LPU inference engine can generate a large 500 tokens per second when working a 7B mannequin. It comes right down to round 250 tokens per second when working a 70B mannequin. This can be a far cry from OpenAI’s ChatGPT, which runs on GPU-powered Nvidia chips that provide round 30 to 60 tokens per second.
Groq is Constructed by Ex-Google TPU Engineers
Groq shouldn’t be an AI chatbot however an AI inference chip, and it’s competing in opposition to business giants like Nvidia within the AI {hardware} area. It was co-founded by Jonathan Ross in 2016, who whereas working at Google co-founded the crew to construct Google’s first TPU (Tensor Processing Unit) chip for machine studying.
Later, many staff left Google’s TPU crew and created Groq to construct {hardware} for next-generation computing.
What’s Groq’s LPU?
The explanation Groq’s LPU engine is so quick compared to established gamers like Nvidia is that it’s constructed totally on a special type of strategy.
In keeping with the CEO Jonathan Ross, Groq first created the software program stack and compiler after which designed the silicon. It went with the software-first mindset to make the efficiency “deterministic” — a key idea to get quick, correct, and predictable ends in AI inferencing.
As for Groq’s LPU structure, it’s much like how an ASIC chip (Utility-specific built-in circuit) works and is developed on a 14nm node. It’s not a general-purpose chip for all types of advanced duties as a substitute, it’s custom-designed for a particular activity, which, on this case, is coping with sequences of knowledge in giant language fashions. CPUs and GPUs, alternatively, can do much more but in addition lead to delayed efficiency and elevated latency.
And with the tailor-made compiler that is aware of precisely how the instruction cycle works within the chip, the latency is lowered considerably. The compiler takes the directions and assigns them to the right place decreasing latency additional. To not overlook, each Groq LPU chip comes with 230MB of on-die SRAM to ship excessive efficiency and low latency with a lot better effectivity.
Coming to the query of whether or not Groq chips can be utilized for coaching AI fashions, as I mentioned above, it’s purpose-built for AI inferencing. It doesn’t characteristic any high-bandwidth reminiscence (HBM), which is required for coaching and fine-tuning fashions.
Groq additionally states that HBM reminiscence results in non-determinacy of the general system, which provides to elevated latency. So no, you can’t practice AI fashions on Groq LPUs.
We Examined Groq’s LPU Inference Engine
You may head to Groq’s web site (visit) to expertise the blazing-fast efficiency with out requiring an account or subscription. At present, it hosts two AI fashions, together with Llama 70B and Mixtral-8x7B. To test Groq’s LPU efficiency, we ran just a few prompts on the Mixtral-8x7B-32K mannequin, which is without doubt one of the finest open-source fashions on the market.
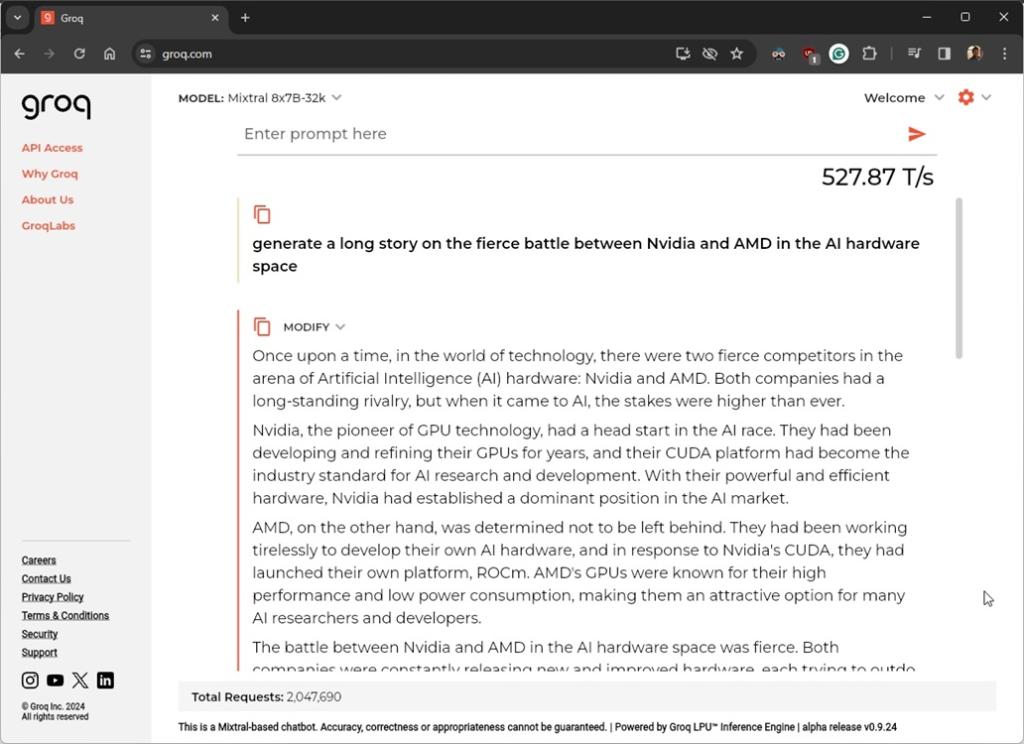
Groq’s LPU generated an incredible output at a velocity of 527 tokens per second, taking only one.57 seconds to generate 868 tokens (3846 characters) on a 7B mannequin. On a 70B mannequin, its velocity is lowered to 275 tokens per second, nevertheless it’s nonetheless a lot larger than the competitors.
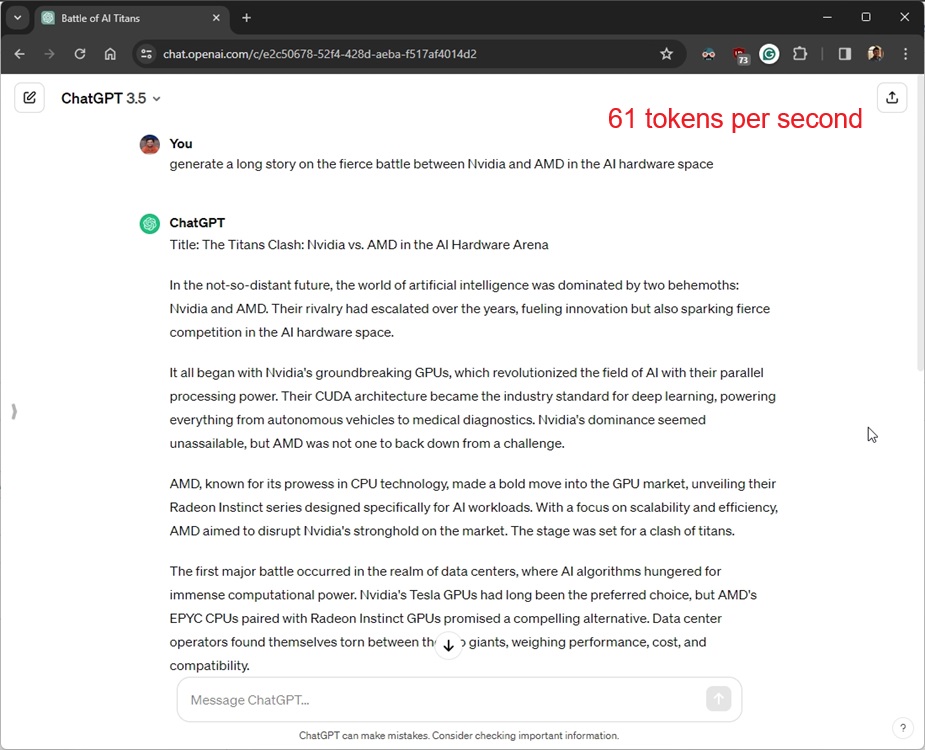
To match Groq’s AI accelerator efficiency, we did the identical take a look at on ChatGPT (GPT-3.5, a 175B mannequin) and we calculated the efficiency metrics manually. ChatGPT, which makes use of Nvidia’s cutting-edge Tensor-core GPUs, generated output at a velocity of 61 tokens per second, taking 9 seconds to generate 557 tokens (3090 characters).
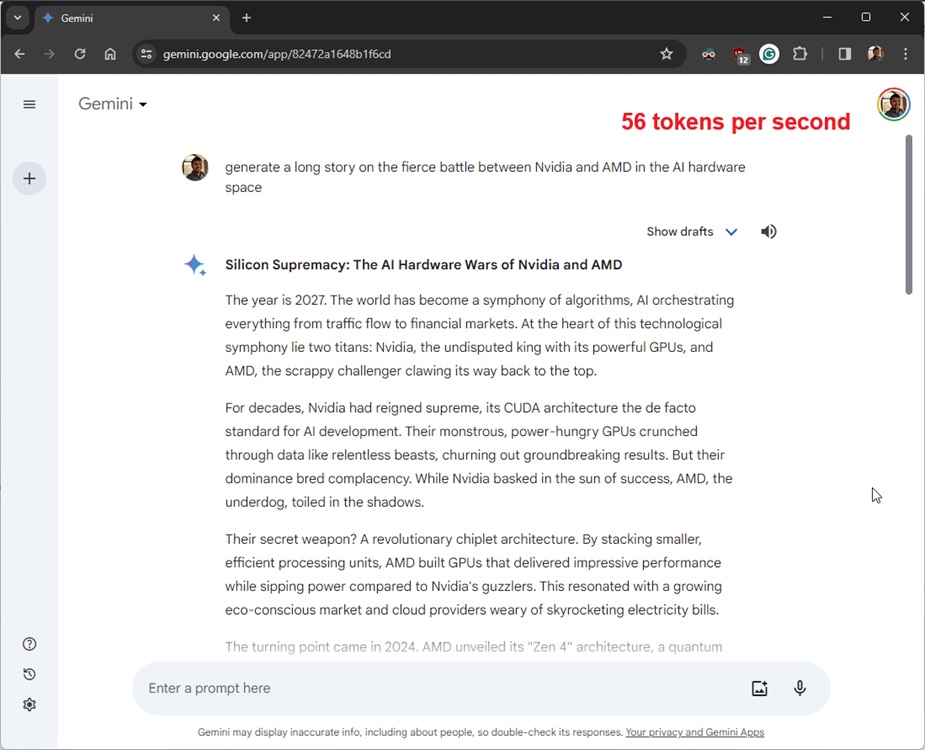
For higher comparability, we did the identical take a look at on the free model of Gemini (powered by Gemini Professional) which runs on Google’s Cloud TPU v5e accelerator. Google has not disclosed the mannequin measurement of the Gemini Professional mannequin. Its velocity was 56 tokens per second, taking 15 seconds to generate 845 tokens (4428 characters).
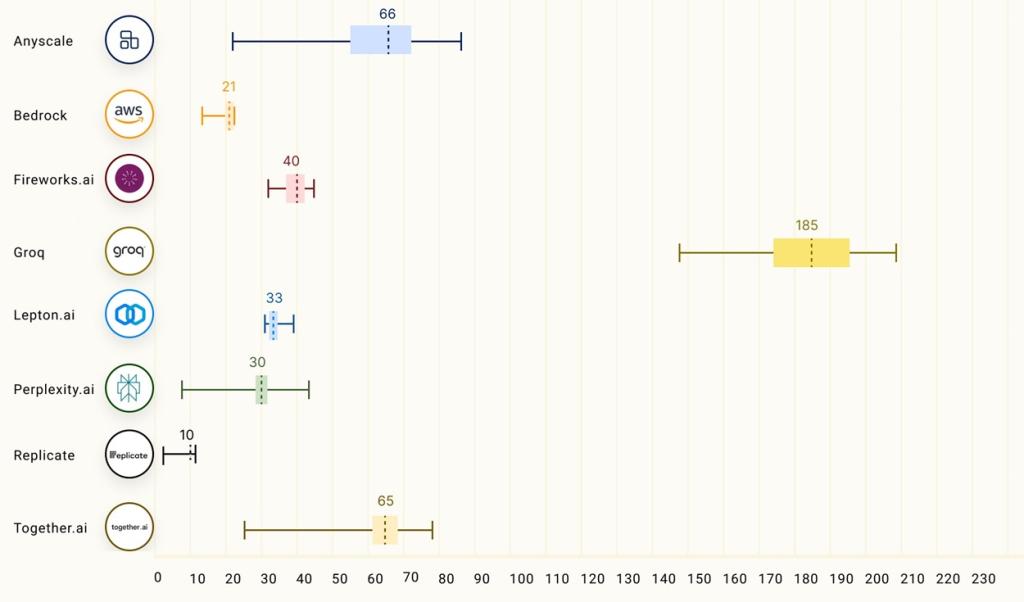
Compared to different service suppliers, the ray-project did an intensive LLMPerf take a look at and located that Groq carried out a lot better than different suppliers.
Whereas we’ve not examined it, Groq LPUs additionally work with diffusion fashions, and never simply language fashions. In keeping with the demo, it may well generate totally different types of photos at 1024px underneath a second. That’s fairly exceptional.
Groq vs Nvidia: What Does Groq Say?
In a report, Groq says its LPUs are scalable and might be linked collectively utilizing optical interconnect throughout 264 chips. It could actually additional be scaled utilizing switches, however it would add to latency. In keeping with the CEO Jonathan Ross, the corporate is growing clusters that may scale throughout 4,128 chips which will probably be launched in 2025, and it’s developed on Samsung’s 4nm course of node.
In a benchmark take a look at carried out by Groq utilizing 576 LPUs on a 70B Llama 2 mannequin, it carried out AI inferencing in one-tenth of the time taken by a cluster of Nvidia H100 GPUs.
Not simply that, Nvidia GPUs took 10 joules to 30 joules of vitality to generate tokens in a response whereas Groq solely took 1 joule to three joules. In summation, the corporate says, that Groq LPUs supply 10x higher velocity, for AI inferencing duties at 1/tenth the price of Nvidia GPUs.
What Does It Imply For Finish Customers?
General, it’s an thrilling improvement within the AI area, and with the introduction of LPUs, customers are going to expertise instantaneous interactions with AI techniques. The numerous discount in inference time means customers can play with multimodal techniques immediately whereas utilizing voice, feeding photos, or producing photos.
Groq is already providing API entry to builders so count on a lot better efficiency of AI fashions quickly. So what do you consider the event of LPUs within the AI {hardware} area? Tell us your opinion within the remark part beneath.